


요약
본 발명은 기존 무선랜 시스템에서 빔포밍 훈련 시간의 비효율성을 해결하기 위해 강화 학습 기반 방법을 통해 송신 섹터를 결정하는 기술입니다. 이는 액션 프레임의 전송 횟수를 최소화하고, 더 많은 단말들의 참여를 가능하게 함으로써 전체 통신 시스템의 효율성을 향상시킵니다. 또한, 딥러닝 네트워크를 이용하여 가치 함수 및 정책 함수의 출력값을 얻고, 최소 손실값을 얻는 가중치로 업데이트합니다. 이를 통해 훈련 시간이 단축되고, 더 많은 단말들이 참여 가능하여 전체 통신 시스템의 효율성 향상 및 경제적 가치를 창출합니다.
키워드: #강화학습 #빔포밍훈련 #통신시스템향상 #딥러닝 #송신섹터결정 #효율성향상 #훈련시간단축 #경제적가치창출 #서비스제공범위확대 #산업경쟁력강화 #무선랜 #AI #MIMO
기본 정보
•
특허명: 강화 학습 기반의 빔포밍 훈련 방법 및 장치
•
발명자: 김문석
•
출원번호: 10-2022-0101909
•
등록번호: 10-2508071
발명의 배경 및 필요성
기술의 배경과 필요성
•
MU-MIMO 빔포밍 훈련은 SISO 단계와 MIMO 단계로 이루어짐
•
효율적인 액션 프레임 전송을 위해 송신 섹터를 위상 배열 안테나에 할당하는 빔포밍 훈련 방법 필요
•
빔포밍 훈련 시간을 증가시키는 모든 송신 섹터 조합으로의 액션 프레임 전송은 비효율적임
•
액션 프레임의 전송 횟수 최소화와 모든 단말의 액션 프레임 수신이 가능한 효율적인 송신 섹터 조합 결정 필요
실험 및 구현
제조 및 구현 과정
•
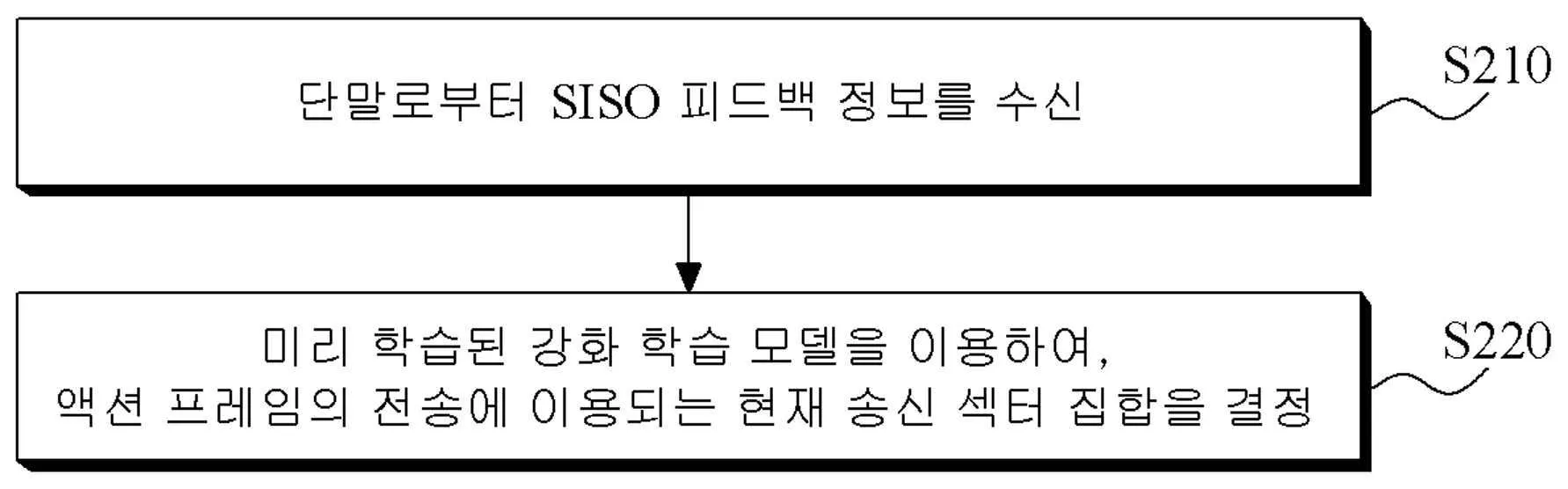
단말로부터 SISO 피드백 정보 수신 후, 강화 학습 모델을 이용해 현재 송신 섹터 집합 결정
•
강화 학습 모델의 상태 집합은 SISO 피드백 정보와 이전 MIMO 단계에서의 액션 프레임 전송에 사용된 이전 송신 섹터 집합 포함
•
액션 집합은 현재 MIMO 단계에 대한 단말의 참여 정보와 현재 송신 섹터 집합에 대한 업데이트 정보 포함
작동 원리 및 실험 절차
•
에이전트는 액세스 포인트에 대응하며, 빔포밍 훈련에 대응하는 환경에서 보상이 최대가 되는 행동 수행
•
이 행동은 현재 송신 섹터 집합을 결정하는 것에 대응
•
SISO 피드백 정보는 k번째 단말에서 수신
•
단말은 모든 송신 섹터의 SNR값을 포함하는 SISO 피드백 정보를 액세스 포인트로 전송
•
참여 정보와 업데이트 정보는 각각 PN, e로 표현
•
액세스 포인트는 업데이트 정보에 따라 현재 송신 섹터 집합을 결정
실험 결과 및 적용 사례
•
BF 훈련 하위 단계에서 액세스 포인트는 현재 송신 섹터 집합의 송신 섹터 조합에 포함된 단말 중에서, 액션 프레임의 수신이 가능한 단말을 확인하여, 송신 섹터 조합을 결정
•
강화 학습 모델의 업데이트 방법은, 액세스 포인트가 강화 학습 모델의 가치 함수와 정책 함수 딥러닝 네트워크를 업데이트하는 것을 포함
발명의 활용 방안
제품과 서비스의 효율적 활용
•
강화 학습 모델을 이용한 발명으로 빔포밍 훈련의 효율성이 향상
•
액션 프레임 전송을 줄여 훈련 시간 단축
•
훈련에 더 많은 단말들이 참여 가능
산업 및 사회적 가치의 창출
•
훈련 시간을 단축하여 전체 통신 시스템의 효율성 향상 및 경제적 가치 창출
•
더 많은 단말들이 참여 가능하게 함으로써 서비스 제공 범위 확대
•
효율성 향상과 서비스 범위 확대로 산업 경쟁력 강화
빔포밍 훈련 관련 시장 동향
통신 시스템 관련 시장 동향
기술 SWOT 분석
Strengths
빔포밍 훈련의 효율성 향상
•
강화 학습 모델을 이용하여 빔포밍 훈련의 효율성을 향상시키는 기술입니다.
•
액션 프레임 전송을 최소화하여 훈련 시간을 단축시킵니다.
Weaknesses
강화 학습 모델의 한계
•
강화 학습 모델은 학습 초기 단계에서는 높은 보상을 받기 어려울 수 있습니다.
•
환경의 변화에 따른 모델의 적응성이 제한적일 수 있습니다.
Opportunities
통신 시스템의 효율성 향상
•
훈련 시간을 단축하여 전체 통신 시스템의 효율성을 향상시킬 수 있습니다.
•
더 많은 단말들이 학습에 참여 가능하게 함으로써 서비스 제공 범위를 확대할 수 있습니다.
Threats
기존 기술과의 경쟁
•
기존의 빔포밍 훈련 방법과의 경쟁에서 밀릴 수 있습니다.
강화 학습 모델의 불확실성
•
강화 학습 모델의 성능은 학습 데이터와 알고리즘에 크게 의존하므로, 예측하지 못한 환경 변화에 취약할 수 있습니다.
Summary
Strengths
•
강화 학습 모델을 이용하여 빔포밍 훈련의 효율성을 향상시키고, 훈련 시간을 단축하며, 더 많은 단말들이 참여할 수 있게 합니다.
Weaknesses
•
강화 학습 모델은 학습 초기 단계에서 높은 보상을 받기 어려울 수 있고, 환경의 변화에 따른 적응성이 제한적일 수 있습니다.
Opportunities
•
훈련 시간을 단축하여 전체 통신 시스템의 효율성을 향상시키고, 서비스 제공 범위를 확대할 수 있습니다.
Threats
•
기존의 빔포밍 훈련 방법과의 경쟁과 강화 학습 모델의 불확실성이 있습니다.
대표도면
세종대학교 산학협력단
(05006) 서울시 광진구 능동로 209 세종대학교 광개토관 1002호
COPYRIGHT (c) 2023 Incheon National University. ALL RIGHT RESERVED.